准备工作 B站排行榜网址:https://www.bilibili.com/v/popular/rank/all &n
准备工作
B站排行榜网址:https://www.bilibili.com/v/popular/rank/all
需要用的的模块引入:requests BeautifulSoup os re
本次只取标题和网址,然后下载到本地
分析网页源码
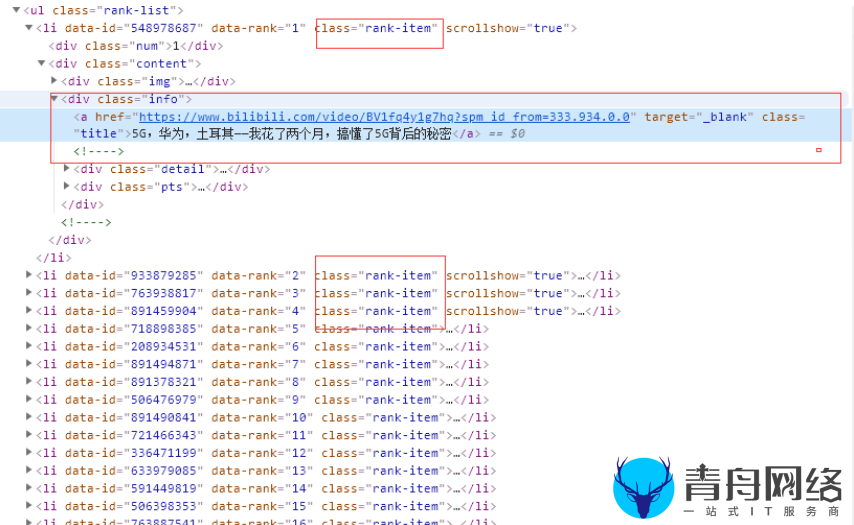
找到共同的class属性 rank-item ,继续分析发现我们要找的数据都在a标签中,那么我们就以a标签上面的<div class="info">来定位获取。直接用css选择器就可以搞定
编写爬虫源码
from bs4 import BeautifulSoup
import requests
import os
import re
json_url = "https://www.bilibili.com/v/popular/rank/all"
class Crawl():
def __init__(self):
# 创建头部信息
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'
}
#获取网址和标题数据
def get_json(self, json_url):
res = requests.get(json_url, headers=self.headers)
# 判断请求状态
soup = BeautifulSoup(res.text, features="lxml")
if res.status_code == 200:
return soup.select('.info a.title')
else:
print('获取失败')
#根据链接下载视频到本地
def download(self, video_url, titlename):
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'
}
res = requests.get(video_url, headers=self.headers)
print(res)
if not os.path.exists('video'):
os.mkdir('video')
if res.status_code == 200:
if os.path.exists('video'):
with open('video/' + titlename + '.mp4', 'wb') as f:
for data in res.iter_content(chunk_size=1024):
f.write(data)
f.flush()
print('下载完成')
else:
print("下载失败")
if __name__ == '__main__':
c = Crawl()
jsondata = c.get_json(json_url)
index = 0
for item in jsondata:
video_url = 'https:' + item.attrs['href']
title = item.text
#去掉标题特殊字符
com = re.compile('[^A-Z^a-z^0-9^\u4e00-\u9fa5]')
titlename = com.sub('', title)
c.download(video_url, titlename)
print(video_url)
index += 1
if index == 5:
break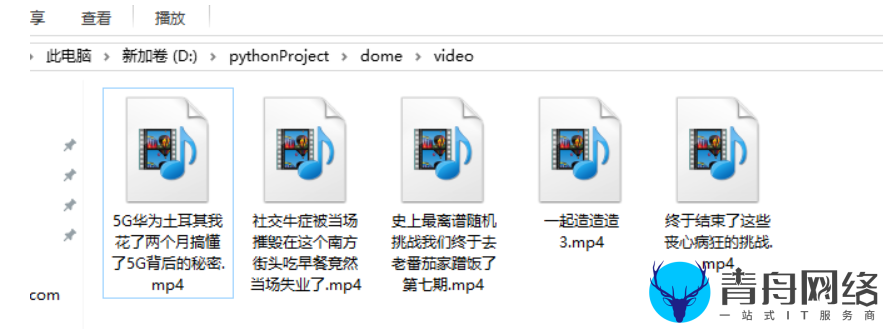
写代码遇到的问题
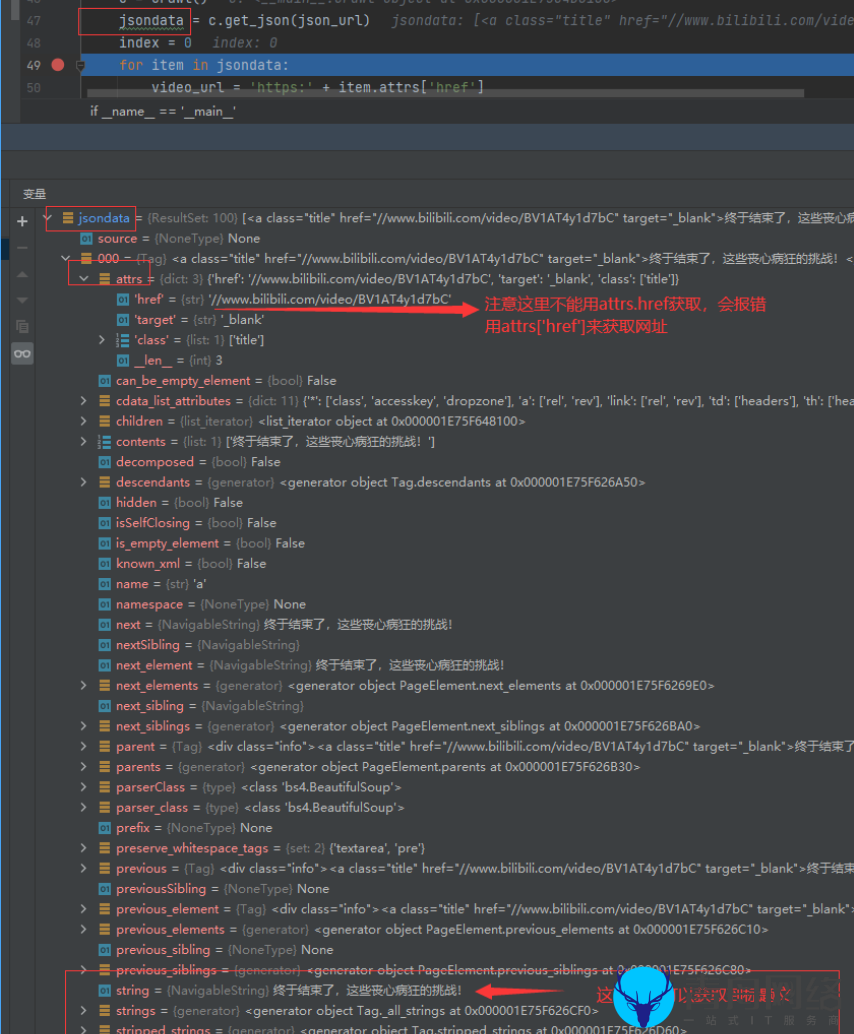
1.我获取到链接但是取不到里面的文本和网址,这时我想到了调试模式和断点,这个真的很有用,附一张我调试截图。
2.写入本地视频文件的时候,发现报错,写入失败,找到原因是标题有特殊字符导致,所以我们需要处理掉那些特殊字符,只留下字母、数字、和汉字。
本文由青舟模板网发布,如若转载,请注明出处:https://www.qingzo.com/jishu/python1.html